2주차 과제 (22.10월 10일 ~ 15일)
1주차 과제
22.10월 10일 ~ 15일
목표
- 자바의 Primitive 타입, 변수 그리고 배열을 사용하는 방법을 익힙니다.
학습할 것
- 프리미티브 타입 종류와 값의 범위 그리고 기본 값
- 프리미티브 타입과 레퍼런스 타입
- 리터럴
- 변수 선언 및 초기화하는 방법
- 변수의 스코프와 라이프타임
- 타입 변환, 캐스팅 그리고 타입 프로모션
- 1차 및 2차 배열 선언하기
- 타입 추론, var
Primitive 타입 종류와 값의 범위 그리고 기본 값
| 타입 | 크기(byte) | 크기(bit) | 값 범위 | 값 범위 표현 2진수 | 기본값 | 비고 |
|---|---|---|---|---|---|---|
| byte | 1byte | 8bit | -128 ~ 127 | -2^7 ~ 2^7 - 1 | 0 | |
| short | 2byte | 16bit | -32,768 ~ 32,767 | -2^15 ~ 2^15 -1 | 0 | |
| singed int | 4byte | 32bit | -2,147,483,648 ~ 2,147,483,647 | -2^31 ~ 2^31 - 1 | ||
| unsinged int | 4byte | 32bit | 0 ~ 4,294,967,295 | 0 ~ 2^32 - 1 | 0 | Java 8부터 가능 |
| singed long | 8byte | 64bit | -9,222,372,036,854,775,808 ~ 9,223,373,036,854,775,807 | -2^63 ~ 2^63 - 1 | 0L | |
| unsinged long | 8byte | 64bit | 0 ~ 4,294,967,295 | 0 ~ 2^64 - 1 | 0L | Java 8부터 가능 |
| char | 2byte | 16bit | 0(’₩u0000’) ~ 65,535(’₩uffff’) | 0 ~ 2^16 - 1 | ₩u0000 | 문자를 내부적으로 유니코드로 저장하기 때문에 정수형과 별반 다르지 않다. |
| float | 4byte | 32bit | 1.4E - 45 ~ 3.4E38 | 1.4 * 10^-45 ~ 3.4 * 10^38 | 0.0f | 실수형은 정수형과 저장방식이 다르기 때문에 훨씬 큰 값을 표현할 수 있지만, 오차가 발생할 수 있다. 실수형은 precision(정밀도)가 있는데 정밀도가 높을수록 오차의 범위가 줄어든다. |
| double | 8byte | 64bit | 4.9E - 324 ~ 1.8E308 | 4.9 * 10^-324 ~ 1.8 * 10^308 | 0.0d | |
| boolean | 1byte | 8bit | true / false | false |
컴퓨터는 전기를 받아서 on/off로 작동된다. on은 1, off는 0으로 표현하기로 약속했다. 그래서 컴퓨터는 2진법(0, 1로 이루어진 수)이 컴퓨터에서 숫자를 표현할 때 가장 적절하다.
따라서 자바의 숫자 타입들은 2의 배수로 범위가 정해진다.
7,15,31,63은 수식으로표현하면 $2^{n} -1$ 표현할 수 있을 것이다.
n은 3부터 증가한다. 즉, 7(=8 - 1), 15(=16 - 1), 31(=32 - 1), 63(=64 - 1)이다.
각 타입이 나타낼 수 있는 숫자의 범위는 2배식 증가한다. 2배씩 증가한다고 기억하자.
더 자세한건 그 전 포스터에 있는 링크를 참고하면 좋겠다 .
Primitive 타입과 Reference 타입
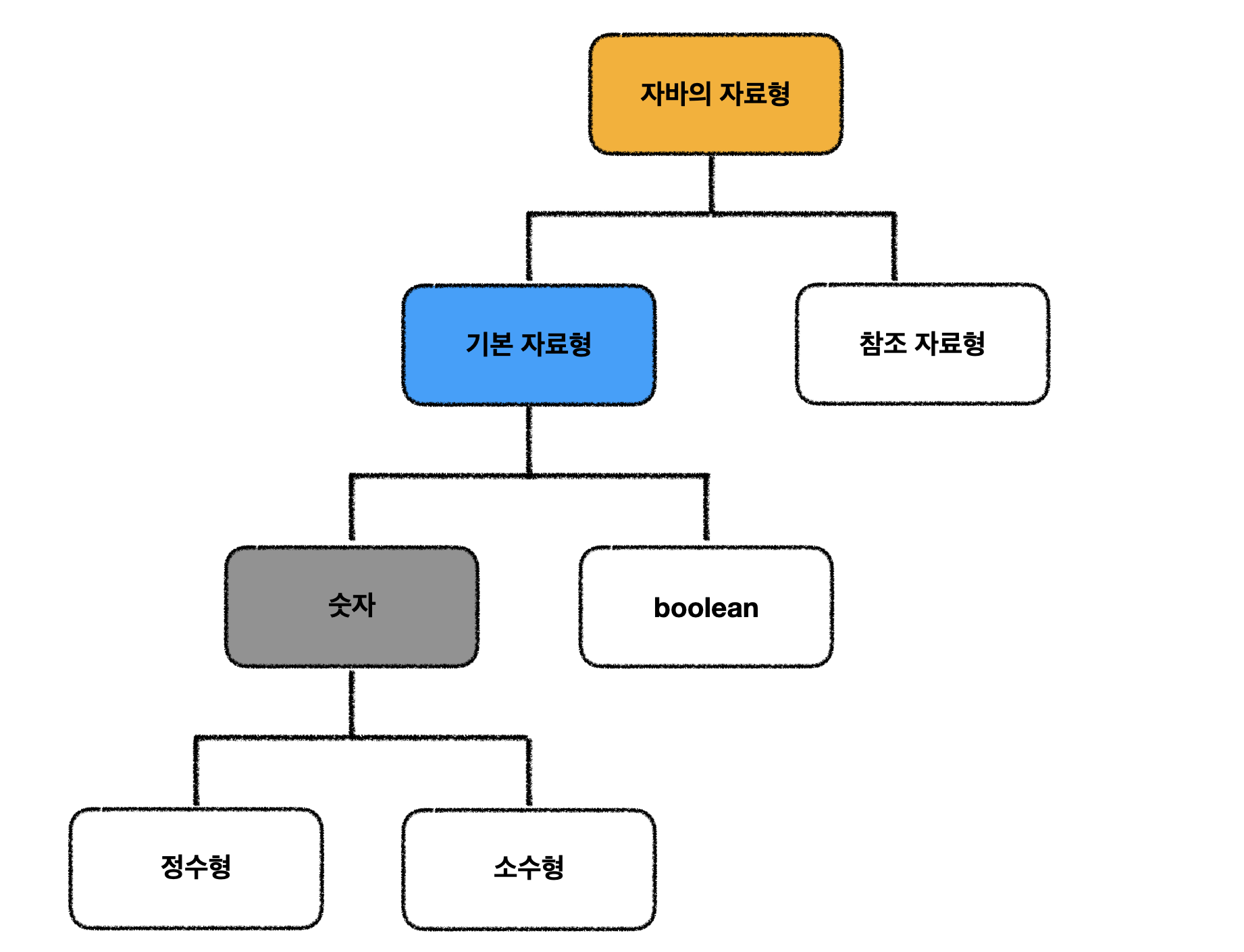
기본형(primitive type)
- 논리형(boolean), 문자형(char), 정수형(byte, short, int, long), 실수형(float, double) 계산을 위한 실제 값을 저장한다.
참조형 (Reference type)
- 객체의 주소를 저장한다. 8개의 기본형을 제외한 나머지 타입.
자료형(data type)과 타입(type)의 차이 ? 기본형은 저장할 값(data)의 종류에 따라 구분되므로 기본형의 종류를 말할 때는
‘자료형(data type)’이라는 용어를 쓴다. 그러나 참조형은 항상'객체의 주소(4 byte 정수)’를 저장하므로 값(data)이 아닌, 객체의 종류에 의해 구분되므로 참조형 변수의 종류를 구분할 때는‘타입(type)’이라는 용어를 사용한다.‘타입(type)’이자료형(data type)’을 포함하는 보다 넓은 의미의 용어이므로 굳이 구분하지 않아도된다.
리터럴
변수나 상수에 저장되는 값 그 자체를 의미한다.
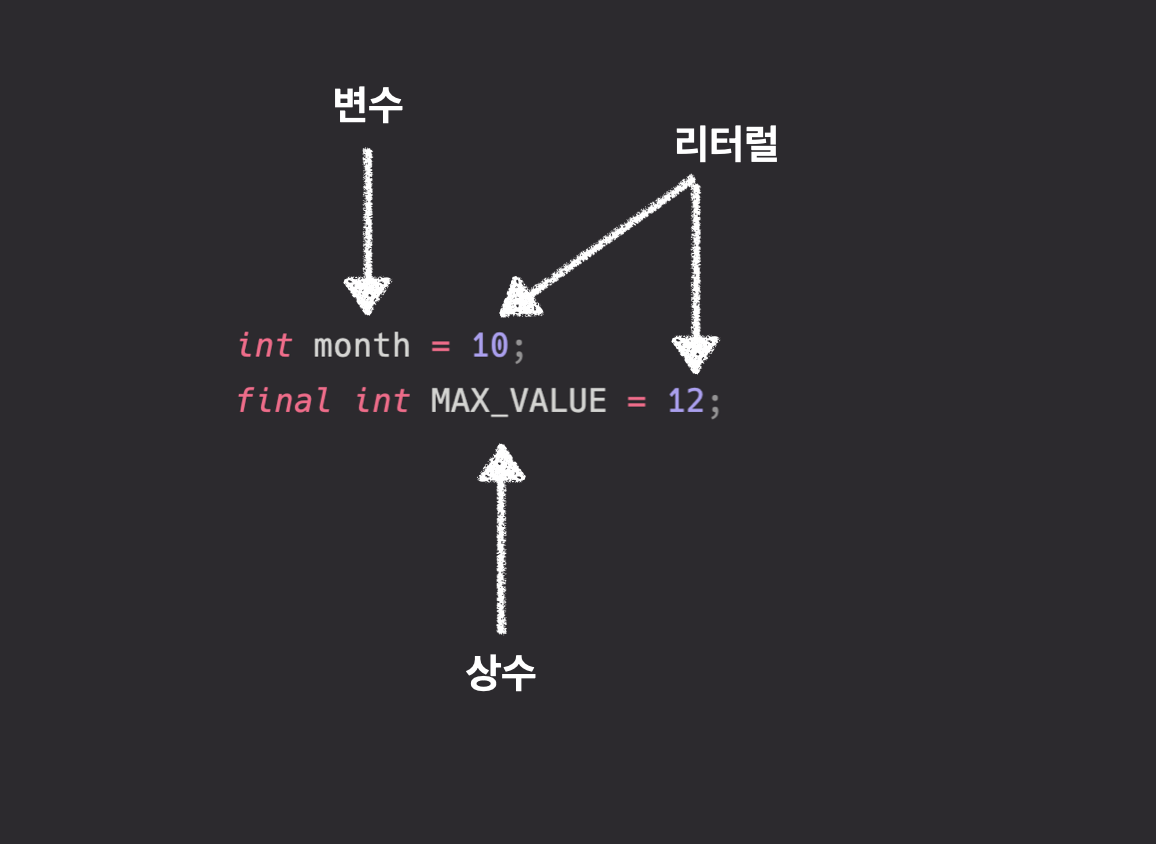
리터럴 종류
- 정수 리터럴
- 실수 리터럴
문자 리터럴
- 리터럴의 타입과 접미사
| 종류 | 리터럴 | 접미사 |
|---|---|---|
| 논리형 | false, true | 없음 |
| 정수형 | 56, 0b111000, 070, 0x38 | L |
| 실수형 | 3.14, 3.0e8, 1.4f, 0x1, 0p-1 | f, d |
| 문자형 | ‘A’, ‘1’, ‘\n’ | 없음 |
| 문자열 | “ABC”, “123”, “A”, “true” | 없음 |
정수 리터럴
- 56이라는 숫자를 10진법, 2진법, 8진법, 16진법으로 표현
int 십진법 = 56; // 10진법
int 이진법 = 0b111000; // 2진법
int 팔진법 = 070; // 8진법
int 십육진법 = 0x38; //16진법
- 정수의 리터럴의 기본형은 int
- Long 타입을 사용하려면 L(대문자),l(소문자)을 붙여줘야한다.
실수 리터럴
float num = 3.14f;
double num2 = 3.0e8; // 3.0 * 10^8
double num3 = 3.0
- 실수의 리터럴의 기본형은 double 타입이고 float는 f를 명시해줘야한다.
문자 리터럴 & 문자열 리터럴
- 문자 리터럴 :
‘a’처럼 작은 따옴표로 된 것을 문자 리터럴이라고한다. - 문자열 리터럴 :
“abc”처럼 큰따옴표로 된것을 문자열 리터럴이라고한다.
char ch = 'a';
String str = "abc";
변수 선언 및 초기화하는 방법
변수의 선언 형식 → 타입 + 변수
int num;
- 변수를 선언한다는 것은 데이터를 메모리에 할당 해준다는 뜻을 의미한다.
변수의 이름 규칙 (네이밍 컨벤션)
- 길이의 제한은 없다
- 첫 문자는 유니코드 문자, 알파벳, $(달러 표시, dollar sign), _(언더스코어, underscore)만 올 수 있다. 보통 변수 이름은 $, _가 처음에 오지는 않음
- 보통 첫문자는 소문자로 시작하는 단어이고, 두번째 단어의 첫 문자만 대문자로 시작한다. (카멜 표기법)
- 상수(constant value)의 경우 모두 대문자로 지정한다. 단어와 단어 사이는 _로 구분한다. (대문자 + 스네이크 표기법)
자바에서는 4가지의 변수가 있다.
- 지역변수(Local Variables)
- 중괄호 내에서 선언된 변수
- 매개 변수(parameter)
- 메소드에 넘겨주는 변수
- 인스턴스 변수(instance variables)
- 메소드 밖에, 클래스 안에 선언된 변수, 앞에는 static이라느 예약어가 없어야 한다.
- 클래스 변수(class variables)
- 인스턴스 변수처럼 메소드 밖에, 클래스 안에 선언된 변수 중에서 타입 선언 앞에 static이라는 예약어가 있는 변수
선언만한 변수는 바이트코드가 어떻게 생겼을까 ?
public class Declaration{
public void declar(){
int a;
}
}
- 변수를 선언만 하였을 때 바이트코드를 살펴보자.
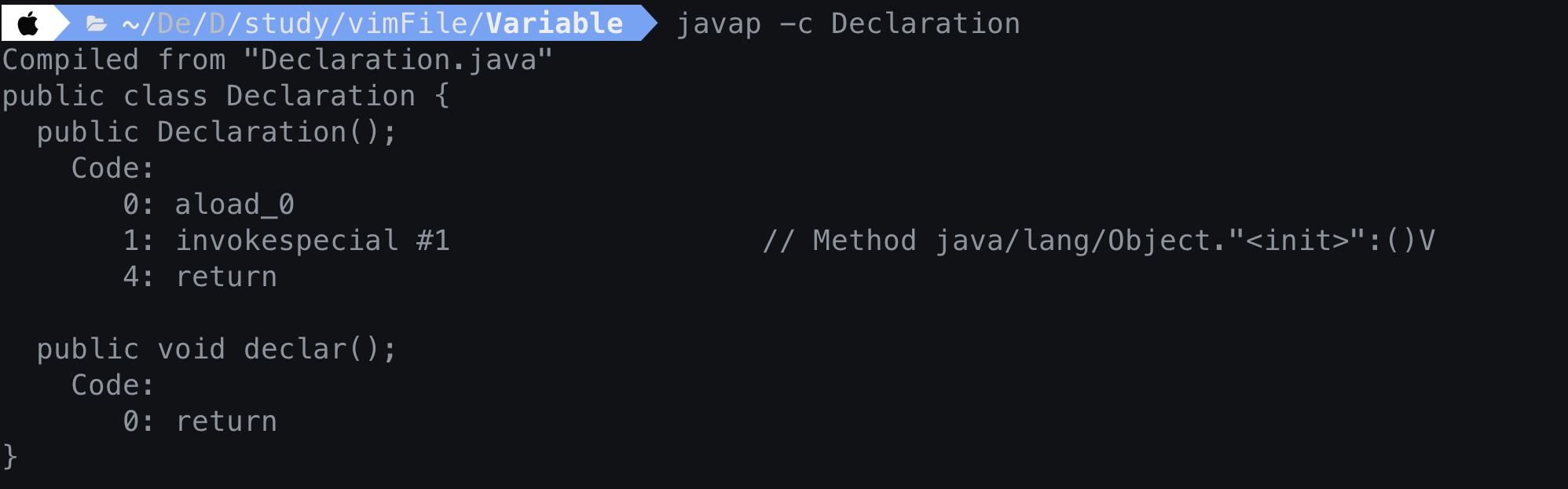
그림을 보면 declar()에 int a를 선언했다. 바로 return 을 해버린다.
여기서 return은 메소드를 수행하고 Stack Frame을 종료한다는 뜻이다.
변수의 초기화
int a = 5;
- 변수를 초기화하고 바이트코드를 해보자.
public class Declaration{
public void declar(){
int a;
a = 5;
}
}
- 초기화까지한 변수를 바이트코드로 변환
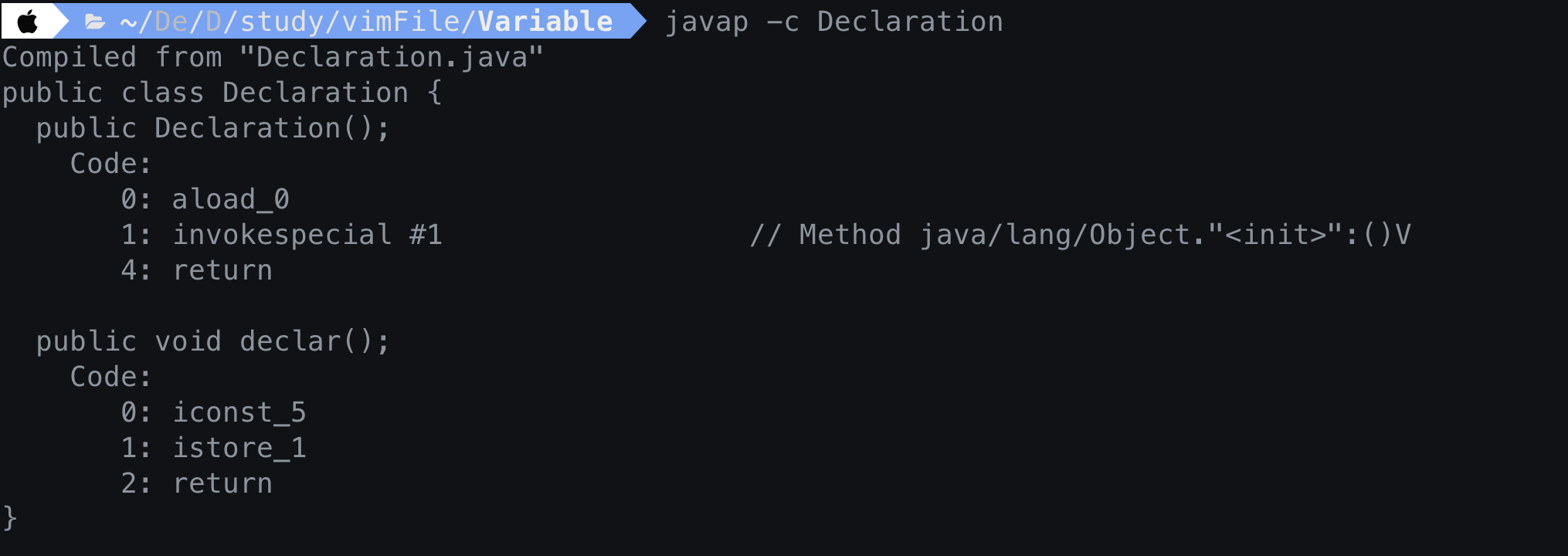
iconst_5는 상수 5 push하라는 것을 의미하는 bytecode이다.istore_1는 Local Variable Section의 1번 인덱스에 값을 저장하라는 것을 의미한다. 그렇게되면 Local Variable Section의 인덱스 1번에상수 5가 들어간다.return은 Stack Frame 종료
변수의 스코프와 라이프타임
| 변수 | 생명주기 | 설명 |
|---|---|---|
| 지역변수(Local Variables) | 지역 변수를 선언한 중괄호 내에서만 유효하다. | 중괄호 내에서 선언된 변수 |
| 매개 변수(parameter) | 메소드가 호출될 때 생명이 시작되고, 메소드가 끝나면 소멸된다. | 메소드에 넘겨주는 변수 |
| 인스턴스 변수(instance variables) | 객체가 생성될 때 생명이 시작되고, 그 객체를 참조하고 있는 다른 객체가 없으면 소멸된다. | 메소드 밖에, 클래스 안에 선언된 변수, 앞에는 static이라느 예약어가 없어야 한다. |
| 클래스 변수(class variables) | 클래스가 처음 호출될 때 생명이 시작되고, 자바 프로그램이 끝날 때 소멸된다. | 인스턴스 변수처럼 메소드 밖에, 클래스 안에 선언된 변수 중에서 타입 선언 앞에 static이라는 예약어가 있는 변수 |
타입 변환, 캐스팅 그리고 타입 프로모션
타입 변환
하나의 타입을 다른 타입으로 바꾸는 것을 타입 변환(type conversion) 이라고 한다.
- Java에서는 다른 타입끼리의 연산은 우선 피연산자들을 모두 같은 타입으로 만든 후에 수행된다.
- 메모리에 할당 받은 바이트의 크기가 상대적으로 작은 타입에서 큰 타입으로의 타입 변환은생략할 수 있다.
- 메모리에 할당 받은 바이트의 크기가 큰 타입에서 작은 타입으로의 타입 변환은 데이터 손실이 발생한다.
타입캐스팅이란?
기본유형의 데이터(primitive type)를 다른 유형의 타입으로 할당하는 것을 말한다.
Widening type cast(automatically)(확대 캐스팅) : 더 작은 데이터 유형을 더 큰 유형 크기로 변환
- byte -> short -> char -> int -> long -> float -> double
- 자동으로 캐스팅이 된다.
public class castingExample2{
public static void main(String[] args){
int i = 100;
long l = i ;
float f = l ;
System.out.println("int value " + i); // 결과 : int value 100
System.out.println("Long value " + l); // 결과 : Long value 100
System.out.println("Float value " + f); // 결과 : Float value 100.0
}
}
- Narrowing Casting (manually)(축소 캐스팅) : 더 큰 데이터 유형을 더 작은 크기 유형으로 변환
- double -> float -> long -> int -> char -> short -> byte
- 명시적으로 수행해야지 된다.
public lcass castingExample{
public static void main(String[] arsg){
char ch = 'c';
int num = 88;
ch = num;
}
}

int num 은 4바이트(32bit)이고 char ch 는 2바이트를 필요로한다. 그렇기 때문에 컴파일 에러가 난다. 4바이트에서 2바이트로 데이터 타입을 바꾸려니 안된다.
- 명시적 변환 하는방법
public class castingExample3{
public static void main(String[] args){
double d = 100.04;
long l = (long)d;
int i = (int)l;
System.out.println("Double value " + d); // 결과 : Double value 100.04
System.out.println("Long value " + l); // 결과 : Long value 100
System.out.println("int value " + i); // 결과 : int value 100
}
}
타입 프로모션(승격?)
- 식을 평가할 때, 중간에 피연산자의 범위를 초과할 수 있기 때문에 자동으로 값이 승격되는데, 이를 타입 프로모션이라고 합니다.
- Java에서는
byte,short,char를 식 평가 할 때 자동으로int로 프로모션 된다. - 피연산자가
long,float,double인 경우 전체 표현식이 각각long,float,double로 프로모션이 된다.
- Java에서는
public class castingExample {
public static void main(String args[]) {
byte b = 42;
char c = 'a';
short s = 1024;
int i = 50000;
float f = 5.67f;
double d = .1234;
double result = (f * b) + (i / c) - (d * s);
System.out.println("result = " + result); //결과 : 626.7784146484375
}
}
1차 및 2차 배열 선언하기
배열의 용도
- 같은 종류의 데이터를 많이 사용해야할 때, 사용하는 기본적인 자료구조
배열의 선언
| 배열의 선언 형식 | 예시 |
|---|---|
| 타입[] 변수명 | int[ ] num |
| 타입 변수명[] | String str[ ] |
배열의 생성
타입[] 변수명 = new 타입[길이];
이러한 배열도 객체이므로, 각각의 배열은 모두 자신만의 필드, 메소드를 가지고 있다.
배열의 초기화
1. 타입[] 배열이름 = {배열요소1, 배열요소2, ...};
2. 타입[] 배열이름 = new 타입[]{배열의 요소1, 배열의 요소2, ...};
int[] arr = new int[]{1,2,3,4}
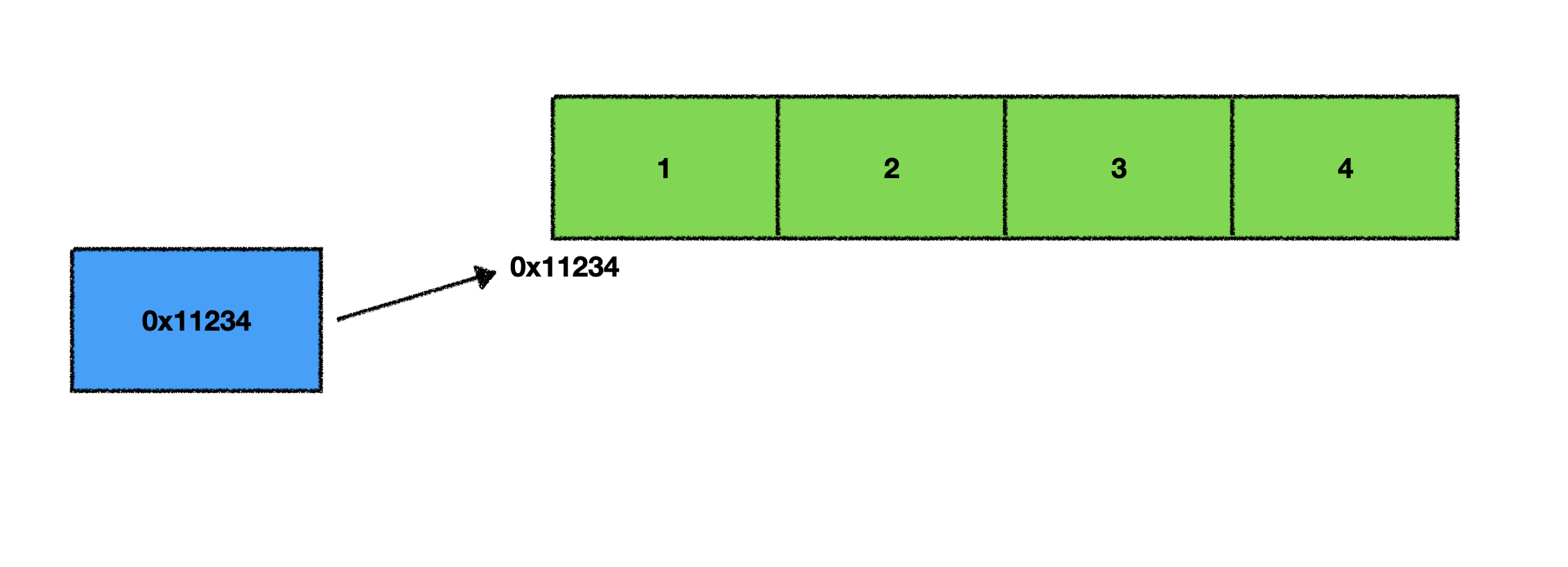
2차원 배열
- 2차원 배열의 선언
타입[][] 변수명;
- 2차원 배열의 초기화
1. 타입[][] 변수명 = {
{ 배열의 요소1, 배열의 요소2,
배열의 요소3 },{ 배열의 요소4 }
};
2. 타입[][] 변수명 = new 타입[][]{ {배열의요소1,배열의 요소2}, {배열의 요소3, 배열의 요소4} }
int arr2 = new int[][]{{1,2} , {3,4}}
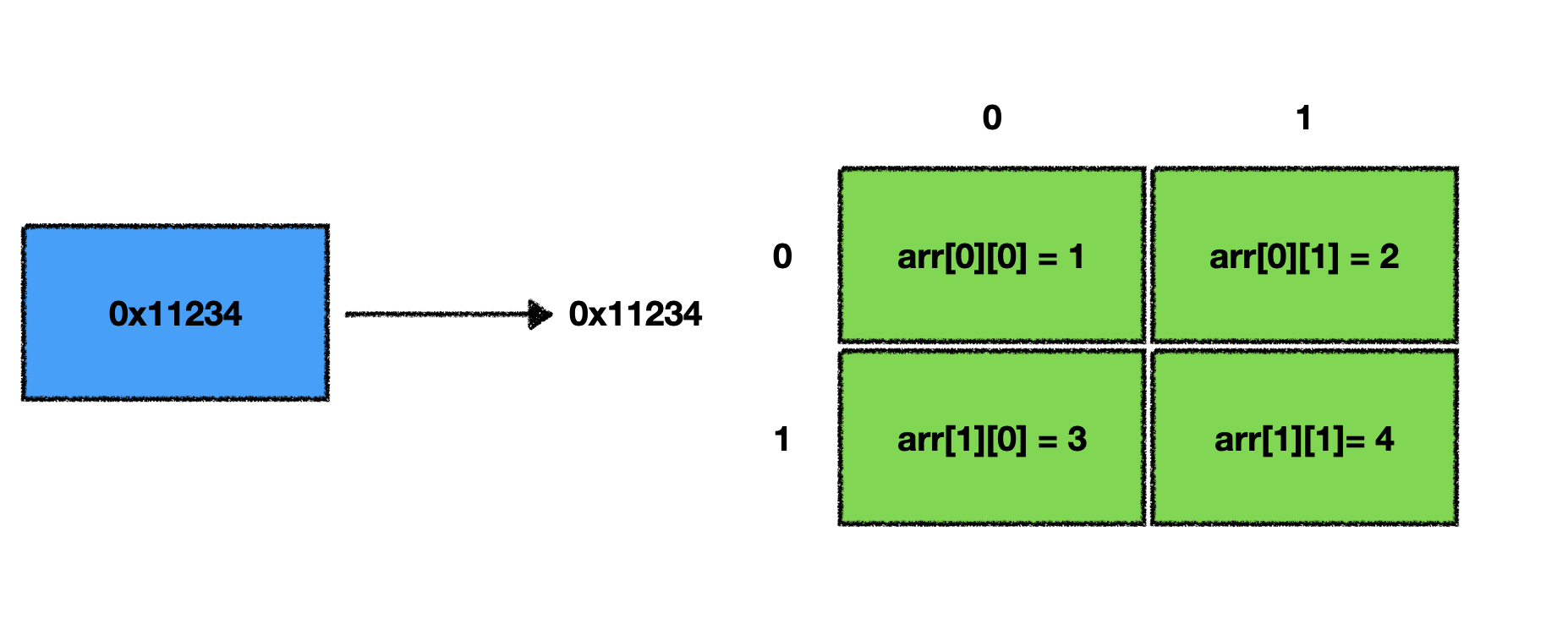
타입 추론, var
- 타입 추론이란? 정적 타이핑을 지원하는 언어로 타입이 정해지지 않은 변수에 대해서 컴파일러가 변수의 타입을 스스로 찾아낼 수 있도록 하는 기능이다.
변수를 명시하지 않아도 되며, 코드의 양을 줄일 수 있는 방법이다.
하지만 나는 의문이다. 자료 중에 가독성을 줄여준다는 말이 있는데 정말 가독성을 줄여줄까? 너무 많은 생략은 오히려 독이 되지않을까? 라는 의구심이 든다.
타입추론 배경
Java 10부터 var 라는 예약어가 생겼다. 컴파일러가 타입 추론을 알아낼 수 있기 때문에타입을 입력할 필요가 없다.
우선 Java 10 전에 있었던 타입 추론을 알아보자.
- Java 5부터 제레릭 메서드 등장. 타입 매개 변수를 추론한다. 추론은 컴파일러가 해준다.
List<Integer> i = Collections.<Integer>emptyList(); // 추론 전
List<Integer> i = Collections.emptyList(); // 추론 후
- 또 다른 예시 : Java 7 부터 다이아몬드 오퍼레이터(
<>) 추가 되었다. 제네릭의 타입 매개변수를 생략할 수 있게 되었다.
Map<String, List<String>> myMap = new HashMap<String,List<String>>(); // <> 사용하기 전
Map<String, List<String>> myMap = new HashMap<>(); // <> 사용 후
- Java 11 에서는 람다식에서도 타입 생략이 있다.
Predicate<String> name = (String x) -> x.length() > 0 // 생략 전
redicate<String> nameValidation = x -> x.length() > 0; // 생략 후
var를 통한 타입 추론
컴파일러는 개발자가 입력한 초기화 값을 통해 타입을 유추한다. 즉, var 예약어는 컴파일러가 타입을 유추할 수 있도록 반드시 데이터를 초기화 해야한다.
public class test01 {
//Java 9
String message = "Hello world";
//Java 10
@Test
void whenIntWithString_thenGetStringTypeVar(){
var message ="Hello";
assertTrue(message instanceof String);
}
}
주의사항
- 초기화가 없이 var는 작동되지 않는다.
- 자바 7에서 나온 다이아몬드 연산자는 var와 함께 사용을 못한다.
var는 어떻게 사용해야지 의미가 있을까 ?
(1)foreach
우리가 리스트를 열거할 때 쓰던 for문, for(Person person : personList) 문에서 변수 선언할 때 var를 쓰면 편하다. IDE에서 for문을 사용할 때 타입 추론하기엔 열거 타입을 정의할 때까지 타입을 직접 작정하거나, 템플릿을 작성해야 해서 난감할 때가 많았다. 이럴 때 var를 써주면 해결해준다 !
for (var person : personList) {
// ...
}
이렇게 될 경우 IDE에서 var 키워드를 Person 클래스로 인식할 수 있는 기회가 주어지게 되고, 컴파일 할 때도 var 키워드를 Person 으로 변환하게 될 것이다.
object타입으로 미리 단정지을 필요도 없다.
(2) 람다 (Java 11)
LTS인 자바 11은 람다 인자에도 var 를 넣게 해주는데, 이게 왜 중요하냐면, 일반 람다의 경우 파라미터 어노테이션을 못 집어 넣는다. 만약 어노테이션을 넣고 싶으면 따로 메소드로 빼던가, 익명 클래스로 정의해야 했었다.
하지만 자바 8부터람다 인자는 타입 추론의 기초였던 게, 자바 11부터는 타입 추론의 유연성을 추가했다.
Consumer<Person> personConsumer = (@Nonnull var person) -> {
// @Nonnull 어노테이션에 의해 person에 널체크부터 하겠지?
}
어노테이션 프로세싱과 어노테이션의 장점만 생각해도 이건 유연성이 증대되는 효과가 있다.
(3) 익명 클래스
일단 보통 가독성 때문에 대부분 개발자들은 아래와 같은 심플한 var 사용을 지양하려고 한다. 이유는 IDE라면 모를까 임시로 자동완성을 지원하지 않는 에디터로 편집할 때 사람이 타입 추론이 어려워서이다.
var intVal = 20;
var strVal = "string";
var list = new ArrayList<Integer>();
하지만 익명 클래스가 나타난다면?
var supply = new Supplier<String>(){
@Override
public String get(){
// 코드
}
}
익명 클래스는 정의가 거대하고, 유추가 쉽다. 그리고 선언한 다음에 변수가 바뀌는 일도 없다.
var 쓰기는 좋다.
하지만 람다는 안된다. 하면 컴파일 오류가 난다.
var supply = () ->{
// 코드 -> 써도 이미 컴파일 오류
}
이유는 람다를 등록할 인터페이스가 모호하기 때문이다.
2주차를 마치며
자바를 깊게 들어가니깐 너무 어렵다. 이게 진정 자바인건가… ? 내가 여태까지 배운 자바는 수박 겉핡기였다. 용어도 익숙하지않는 용어들이 나온다. 계속 보면서 익숙해져야겠다. 진짜 자바 어렵구나…. 다음주는 연산자인거 같다. 호우….. 끝까지 하는게 중요하다. 천천히 하자
참고
- https://www.edureka.co/blog/type-casting-in-java/#WhatisTypeCasting?
- 이상민 지음, 자바의 신 1편
- http://www.tcpschool.com/java/java_datatype_typeConversion
- https://www.geeksforgeeks.org/type-conversion-java-examples/
- https://developers.redhat.com/blog/2018/05/25/simplify-local-variable-type-definition-using-the-java-10-var-keyword
- https://velog.io/@dion/백기선님-온라인-스터디-2주차-자바-데이터-타입-변수-그리고-배열#학습할-것
- https://dev.to/composite/java-10-var-3o67