Chapter 4
스트림 소개
- 이 장의 내용
- 스트림이란 무엇인가 ?
- 컬렉션과 스트림
- 내부 반복과 외부 반복
- 중간 연산과 최종 연산
스트림을 알기 전에 컬렉션의 개념을 한번 정리하고 가자.
컬렉션은 데이터를 그룹화하고 처리할 수 있다. 대부분의 프로그래밍 작업에 사용된다.
예를 들어 메뉴를 구성하는 요리 컬렉션이 있는데 컬렉션의 요리를 반복하면서 각 요리의 칼로리양을 더 한다.
어떤 사람은 컬렉션에서 칼로리가 적은 요리만 골라 특별 건강 메뉴를 구성하고 싶을지도 모른다.
대부분의 자바 애플리케이션에서는 컬렉션을 많이 사용하지만 완벽한 컬렉션 관련 연산을 지원하려면 한참 멀었다.
대부분의 비지니스 로직에는 요리를 카테고리(예시 - 채식주의자용)로 그룹화 하든가 가장 비싼 요리를 찾는 등의 연산이 포함된다. 대부분의 데이터베이스에서는 선언형으로 이와 같은 연산을 표현할 수 있다. 예를 들면 SELECT name FROM dishs WHERE calorie < 400 이라는 문장은 칼로리가 낮은 요리명을 선택하라는 SQL 질의다. SQL 질의에서 알 수 있듯이 요리의 속성을 이용하여 어떻게 필터링할 것인지는 구현할 필요가 없다.(예를 들어 자바처럼 반복자, 누적자 등을 이용할 필요가 없다.) SQL 질의 언어에서는 우리가 기대하는 것이 무엇인지 직접 표현할 수 있다. 즉, SQL에서는 질의를 어떻게 구현해야 할지 명시할 필요가 없으며 구현은 자동으로 제공된다. 컬렉션으로도 이와 비슷한 기능을 만들 수 있지 않을까?
많은 요소가 포함하는 커다란 컬렉션은 어떻게 처리해야 할까 ?
성능을 높이려면 멀티코어 아키텍쳐를 활용해서 병렬로 컬렉션의 요소를 처리해야 한다. 하지만 병렬 처리 코드를 구현하는 것은 단순 반복 처리 코드에 비해 복잡하고 어렵다. 게다가 복잡한 코드는 디버깅도 어렵다.
앞서 말한 내용을 해결할 방법은 무엇일까? 바로 .. 자바 8에서 나온…
해결책 : Stream
그렇다면
스트림이란 무엇일까 ?
스트림(Streams)은 자바 8 API에서 새로 추가된 기능이다. 스트림을 이용하면 선언형으로 컬렉션 데이터를 처리할 수 있다.
말로 보다 예제를 통해서 하는 것이 빠르다. 자 들어가 보자.
- 다음 예제는 저칼로리의 요리명을 반환하고, 칼로리를 기준으로 요리를 정렬하는 자바 7 코드다. 이 코드를 자바 8의 스트림을 이용해서 다시 구현해보자..
자바7 코드
List<Dish> lowCaloricDishs = new ArrayList<>();
for(Dish dish : menu) { //<-- 누적자로 요소 필터링
if(dish.getCalorics() < 400) {
losCaloricDishs.add(dish);
}
}
Collections.sort(lowCaloricDishes, new Comparator<Dish>() { //<-- 익명 클래스로 요리 정렬
public int compare(Dish dish1, Dish dish2){
return Integer.comare(dish1.getCalorics(), dish2.getCalories());
}
});
List<String> lowCaloricDisheName = new ArrayList<>();
for(Dish dish : lowCaloricDishes) {
lowCaloricDishsName.add(dis.getName()); //<-- 정렬된 리스트를 처리하면서 요리 이름 선택
}
위 코드에서는 lowCaloricDishs라는 ‘가비지 변수’를 사용했다.
즉, lowCaloricDishs는 컨테이너 역할만 하는 중간 변수다.
자바 8에서 이러한 세부 구현은 라이브러리 내에서 모두 처리한다.
자바 8 코드
import static java.util.Comparator.comparing;
import static java.util.strem.Collectors.toList;
List<String> lowCaloricDishsName = menu.**stream()**
.filter(d -> d.getCalories() < 400 ) // <-- 400 칼로리 이하의 요리 선택
.sorted(comparing(Dish::getCalories)) // <-- 칼로리로 요리 정렬
.map(Dish::getName) // <-- 요리명 추출
.collect(toList()); // <--모든 요리명을 리스트에 저장
스트림의 새로운 기능이 주는 이점
- 선언형으로 코드를 구현할 수 있다.
- loop와 if 조건문 등의 제어 블록을 사용해서 어떻게 동작을 구현할지 지정할 필요 없이 ‘저칼로리의 요리만 선택하라’ 같은 동작의 수행을 지정할 수있다.
- 선연형 코드와 동작 파라미터화를 활용하면 변하는 요구항상에 쉽게 대응할 수 있다.
- filter, sorted, map, collect 같은 여러 빌딩 블록 연산을 연결해서 복잡한 데이터 처리 파이프라인을 만들 수 있다. 여러 연산을 파이프라인으로 연결해도 여전히 가독성과 명확성이 유지된다.
- filter() 결과→ sorted() 결과 → map() 결과→ collect()로 연결
filter, sorted, map, collect 같은 연산은 고수준 빌딩 블록(high-level building block)으로 이루어져 있으므로 특정 스레딩 모델에 제한되지 않고 자유롭게 어떤 상황에서든 사용할 수있다. (이들은 내부적으로 단일 스레드 모델에 사용할 수 있지만 멀티코어 아키텍쳐를 최대한 투명하게 활용할 수 있게 구현되어 있다.)
결과적으로 우리는 데이터 처리 과정을 병렬화하면서 스레드와 락을 걱정할 필요가 없다. 이 모든 것이 Stream API 덕분이다.
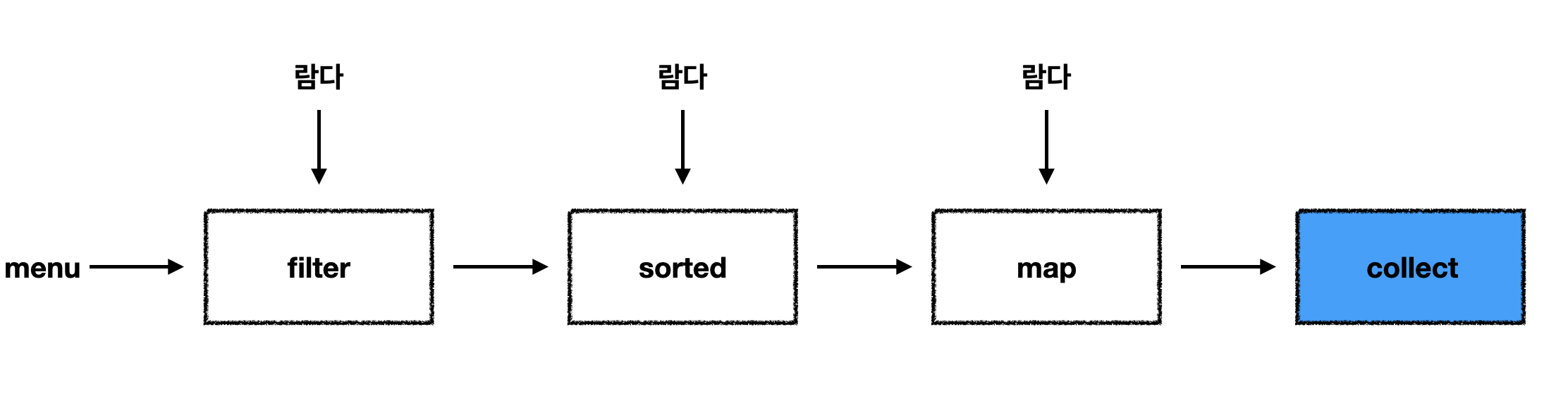
자바 8의 스트림 API의 특징
- 선언형 : 더 간결하고 가독성이 좋아진다.
- 조립할 수 있음 : 유연성이 좋아진다.
- 병렬화 : 성능이 좋아진다.
다음 코드의 요리 리스트, 즉 메뉴를 주요 예제로 사용하겠다.
import java.util.Arrays;
import java.util.List;
public class Dish {
private final String name;
private final boolean vegetarian;
private final int calories;
private final Type type;
public Dish(String name, boolean vegetarian, int calories, Type type) {
this.name = name;
this.vegetarian = vegetarian;
this.calories = calories;
this.type = type;
}
public String getName() {
return name;
}
public boolean isVegetarian() {
return vegetarian;
}
public int getCalories() {
return calories;
}
public Type getType() {
return type;
}
@Override
public String toString() {
return name;
}
public enum Type{
MEAT, FISH, OTHER
}
List<Dish> menu = Arrays.asList(
new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("chicken", false, 400, Dish.Type.MEAT),
new Dish("french fries",true, 530, Dish.Type.OTHER),
new Dish("rice",true,350, Dish.Type.OTHER),
new Dish("season fruit",true,120, Dish.Type.OTHER),
new Dish("pizza",true,550, Dish.Type.OTHER),
new Dish("parwns",false,300, Dish.Type.FISH),
new Dish("salmon",false,450, Dish.Type.FISH)
);
}
스트림 시작하기
스트림이란 정확히 무엇일까 ?
스트림이란 ‘데이터 처리 연산을 지원하도록 소스에서 추출된 연손된 요소(sequence of elements)로 정의한다.
- 연속된 요소
- 컬렉션과 마찬가지로 스트림은 특정 요소 형식으로 이루어진 연속된 값 집합의 인터페이스를 제공한다. 컬렉션은 자료구조이므로 컬렉션에서는 (예를 들어 ArrayList를 사용할 것인지 아니면 LinkedList를 사용할 것인지에 대한) 시간과 공간의 복잡성과 관련된 요소 저장 및 접근 연산이 주를 이룬다.
- 소스
- 스트림은 컬렉션, 배열, I/O 자원 등의 데이터 제공 소스로부터 데이터를 소비한다. 정렬된 컬렉션으로 스트림을 생성하면 정렬이 그대로 유지된다. 즉, 리스트로 스트림을 만들면 스트림의 요소는 리스트의 요소와 같은 순서를 유지한다.
- 데이터 처리 연산
- 스트림은 함수형 프로그래밍 언어에서 일반적으로 지원하는 연산과 데이터베이스와 비슷한 연산을 지원한다. 예를 들어 filter, map, reduce, find, match, sort 등으로 데이터를 조작할 수 있다.
- 스트림 연산은 순차적으로 또는 병렬로 실행할 수 있다.
- 파이프 라이닝(Pipelining)
- 대부분의 스트림 연산은 스트림 연산끼리 연결해서 커다란 파이프라인을 구성할 수 있도록 스트림 자신을 반환한다. 그 덕분에 게으름(laziness), 쇼트서킷(short-circuiting)같은 최적화도 얻을 수 있다. 연산 파이프라인은 데이터 소스에 적용하는 데이터베이스 질의와 비슷하다.
- 내부 반복
- 반복자를 이용해서 명시적으로 반복하는 컬렉션과 달리 스트림은 내부 반복을 지원한다.
import static java.util.stream.Collectors.toList;
List<String> threeHighCaloricDishName = menu.stream() // <-- 메뉴(요리 리스트)에서 스트림을 얻는다.
.filter(dish -> dish.Calories() > 300) // <-- 파이프라인 연산 만들기. 첫 번째로 고칼로리 요리를 필터링한다.
.map(Dish::getName) // <-- 요리명 추출
.limit(3) // <-- 선착순 세 개만 출력
.Collect(toList()); // <-- 결과를 다른 리스트로 저장
System.out.println(threeHighCaloricDishNames); // <-- 결과 : [pork, beef, chicken]
요리 리스트를 포함하는 menu에 stream메서드를 호출해서 스트림을 얻었다.
여기서 데이터 소스는 요리 리스트(메뉴)다. 데이터 소스는 연속된 요소를 스트림에 제공한다.
다음 스트림에 filter, map, limit, collect로 이어지는 일련의 데이터 처리 연산을 적용한다.
collect를 제외한 모든 연산은 서로 파이프라인 을 형성할 수 있도록 스트림을 반환한다. 파이프 라인은 소스에 적용하는 질의 같은 존재다.
마지막으로 collect 연산으로 파이프라인을 처리해서 결과를 반환한다.
여기서 collect는 스트림이 아니라 List를 반환한다.
마지막에 collect를 호출하기 전까지는 menu에서 무엇도 선택되지 않으며 출력 결과도 없다.
즉, collect가 호출되기 전까지 메서드 호출이 저장되는 효과가 있다.
- filter
- 람다를 인수로 받아 스트림에서 특정 요소를 제외시킨다.
- map
- 람다를 이용해서 한 요소를 다른 요소로 변환하거나 정보를 추출한다.
- limit
- 정해진 개수 이상의 요소가 스트림에 저장되지 못하게 스트림 크기를 축소 truncate한다.
- collect
- 스트림을 다른 형식으로 변환한다.
- 스트림에서 메뉴를 필터링해서 세 개의 고칼로리 요리명 찾기
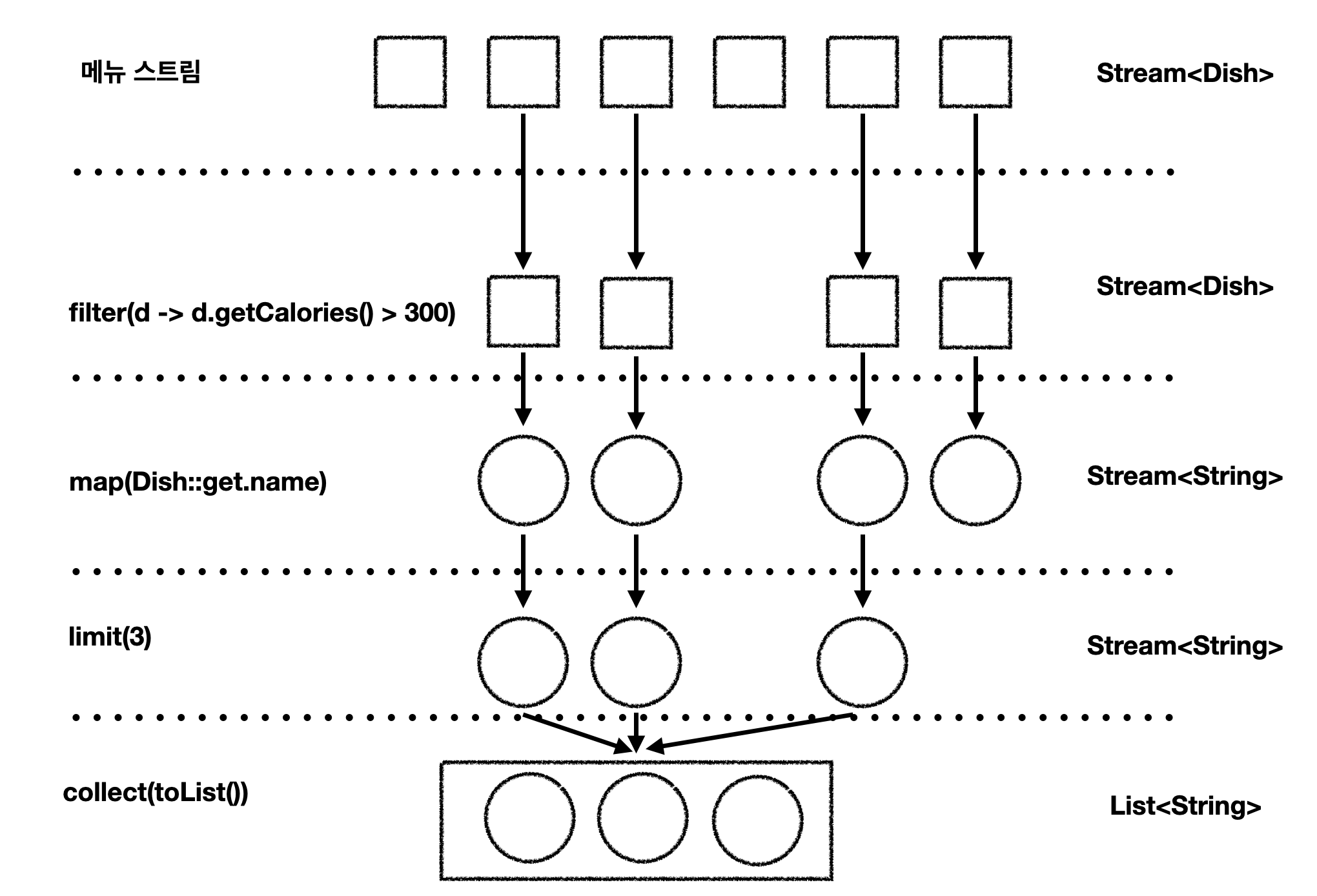
스트림 라이브러리에서 필터링(filter), 추출(map), 축소(limit) 기능을 제공하므로 직접이 기능을 구현할 필요가 없었다.
결과적으로 스트림 API는 파이프라인을 더 최적화할 수 있는 유연성을 제공한다.
스트림과 컬렉션
자바의 기존 컬렉션과 새로운 스트림 모두 연속된 요소 형식의 값을 저장하는 자료구조의 인터페이스를 제공한다.
여기서 ‘연속된(sequenced)’ 이라는 표현은 순서와 상관없이 아무 값에나 접속하는 것이 아니라 순차적으로 값에 접근한다는 것을 의미한다.
- 컬렉션과 스트림의 차이점
- 이해를 돕기위해 일상적인 예시를 들어보자.
USB에 어떤 영화가 저장되어 있다 하자. USB에 전체 자료구조가 저장되어 있으므로 USB도 컬렉션이다. 다음은 인터넷 스트리밍으로 같은 비디오를 시청한다고 하자. 스트리밍, 즉 스트림이다.스트리밍으로 비디오를 재생할 때는 사용자가 시청하는 부분의 몇 프레임을 미리 내려받는다. 그러면 스트림의 다른 대부분의 값을 처리하지 않은 상태에서 미리 내려받은 프레임부터 재생할 수 있다. 특히 비디오 재생기에는 모든 프레임을 메모리에 컬렉션으로 저장할 수 있는 충분한 메모리가 없을 수도 있으며, 충분한 메로리가 있더라도 모든 프레임을 내려받은 다음에 재생을 시작하면 재생을 시작하기까지 아주 오랜 시간이 걸릴 수 있다.
컬렉션과 스트림의 가장 큰 차이는 데이터를 언제 계산하느냐가 큰 차이다.
- 컬렉션은 현재 자료구자가 포함하는 모든 값을 메모리에 저장하는 자료구조이다. 즉, 컬렉션의 모든 요소는 컬렉션에 추가하기 전에 계산되어야 한다(컬렉션에 요소를 추가하거나 컬렉션의 요소를 삭제할 수 있다. 이런 연산을 수행할 때마다 컬렉션의 모든 요소를 메모리에 저장해야 하며 컬렉션에 추가하려는 요소는 미리 계산되어야한다.).
- 반면 스트림은 이론적으로
요청할 때만 요소를 계산하는 고정된 자료구조다.(스트림에 요소를 추가하거나 스트림에서 요소를 제거할 수 없다) 이러한 스트림의 특성은 프로그래밍에 큰 도움을 준다. 결과적으로 스트림은 생성자(producer)와 소비자(consumer)관계를 형성한다. - 스트림은 게으르게 만들어지는 컬렉션과 같다. 즉 사용자가 데이터를 요청할 때만 값을 계산한다. (경영학에서는 이를 요청 중심 제조 또는 즉석 제조라고 부른다고한다. )
- 반면 컬렉션은 적극적으로 생성된다(생산자 중심supplier-driven : 팔기도 전에 창고를 가득 채움). 소수 예제에 이를 적용해보자. 컬렉션은 끝이 없는 모든 소수를 포함하려 할 것이므로 무한 루프를 돌면서 새로운 소수를 계산하고 추가하기를 반복할 것이다. 결국 소비자는 영원히 결과를 볼 수 없게 된다.
- 이해를 돕기위해 일상적인 예시를 들어보자.
- 또 다른 예로는 브라우저 인터넷 검색이 있다.
- 구글이나 전자상거래 온라인상점에서 검색어를 입력했다고 가정하자. 그림을 포함한 모든 검색 결과를 내려받을 때까지 기다리지 않아도 가장 비슷한 10개 또는 20개의 결과 요소를 포함하는 스트림을 얻을 수 있다(다음 10개 또는 20개의 결과를 확인할 수 있는 버튼과 함께). 소비자가 다음 10개 버튼을 누르면 발행자는 여러분의 요청을 받아서 이를 계산한 다음에 여러분 브라우저에 표시할 것이다.
- 딱 한 번만 탐색할 수 있다.
반복자와 마찬가지로 스트림도 한 번만 탐색할 수 있다. 즉, 탐색된 스트림의 요소는 소비된다. 반복자와 마찬가지로 한 번 탐색한 요소를 다시 탐색하려면 초기 데이터 소스에서 새로운 스트림을 만들어야 한다(그럴려면 컬렉션처럼 반복 사용할 수 있는 데이터 소스여야 한다. 만일 데이터 소스가 I/O 채널이라면 소스를 반복 사용할 수 없으므로 새로운 스트림을 만들 수 없다.)
List<String> title = Arrays.asList("Java8", "In", "Action"); Stream<String> s = title.stream(); s.forEach(System.out::println); // <-- title의 각 단어를 출력 s.forEach(System.out::println); // <-- java.lang.IllegalStateException: 스트림이 이미 소비되었거나 닫힘
명심하기 스트림은 단 한번만 소비할 수 있다는 점..!!
컬렉션과 스트림의 또 다른 차이점은 데이터 반복 처리 방법이다.
스트림을 배우고 …
우선 스트림이란 것을 추상적으로 알고 있던 개념을 이번 기회에 조금 구체적으로 익혔다. 이제 이걸 응용해봐야겠다. 알고리즘 문제풀 때 쉬운 문제들로 스트림에 접근해보자… 😅😅
들어가기 앞서 스트림이라는 것이 다가오는 느낌은 기계 같은 느낌일꺼 같다? 그리고 SQL질의 같다는 생각이 많이 들긴했는데 예제에서도 그렇게 설명하는 것을 보고 어느정도 맞춤거에 있어서 뿌듯..
